
The basic processes leading to systems integration are interface concept exploration, interface definition, interface management, and interface implementation. To understand systems integration, we need to understand interfaces and how they’re managed throughout systems development processes and activities. But the word ‘interface’ is often taken in different contexts and used to refer to various abstractions and concepts in and outside of software systems development practices.
You may know interfaces in terms of interface-based development in highly object-oriented systems development, where they act as programming abstractions containing functions that require those who inherit from one to implement said functions. You may know APIs in terms of getting data from or sending data to various IP address endpoints.
In terms of the more generalized field of systems engineering and development, an interface has a more abstract, conceptual meaning from which those abstractions are derived – which is to describe the set of methods, data, and value elements various system elements used to interact with one another.
You can think of all interfaces from a conceptual standpoint as a presumed ‘contract’ – a set of operations/functions that a whole system, subsystem, or system element agrees to implement, and which imply needed data or value elements of a particular structure or type. ‘Implementing’ an interface means that the system element agrees to the contract. In a model, since blocks, classes, etc. are generalized versions of the real-world objects/instances they represent, the interfaces they are connected to implies the real-world objects will provide those agreed upon services in the standardized way provided by the interface.
Interfaces, like system elements, can exist at varying levels of generalization and abstraction:
Interfaces allow for standardization/common specification (think, for example, of the various couplings, screws, nails, bolts, washers and more you see of different sizes you see at a hardware store – and how those implement various interfaces in various ways to meet assembly specifications).
Interfaces can vary widely in ‘shape, size, and function’ to meet the desired use cases, and may even be polymorphic (especially in OOSEM/OOP).
In software development, we need to consider similarly, how to manage, architect, design, and implement the interfaces in our system such that they can be traced back to and help to validate and eventually fulfill the provided needs, objectives, and goals of a system and the requirements derived from those.
In considering the future scalability and maintainability of our systems, defining interfaces is very important – especially in fields with very abstract system elements, such as software development. Definition of interfaces, what they entail, and what they seek to translate between elements (in terms of software, usually information) helps us to decouple elements, factor functionality/functions, and increase the internal cohesion and purpose inherent to the definition of each system element.
If a conceptual interface is a description/definition of how whole systems, subsystems, and system elements interact with one another by defining or modeling the set of methods, data, and value elements provided, then Systems Integration is the act of implementing modeled or described conceptual interfaces via selection, configuration, programming, and use of some technology to realize them.
API stands for "Application Programming Interface".
A definition for software folks:
A way for software system elements to expose resources (usually data or functions - either belonging to it or not) to external systems or subsystems programmatically.
This normally is performed by establishing a ‘client-server’ relationship over the web using computer networking technologies. Other kinds of interfaces exist to implement APIs internally within a system, some of which can be considered ‘true’ APIs (such as in the case of a lightweight API framework applied to microservices running in virtualized containers, such as docker containers), but the term ‘API’ is generally used to refer to a software system interface designed for interaction with external systems.
In terms of the larger realm of systems engineering and development, an API for software systems can be defined as an interface between software applications, to be implemented in a programming language, with interactions occurring during the software runtime – usually over a physical computer network.
Let’s break down the term:
Application
This refers to a whole software runtime, hosted on some infrastructure implied to have networking access and capabilities (can ‘listen’ for and intercept network activity on specified ports) or integration with a service that does. The API might not exist in the same ‘location’ as the application, whereas ‘application’ itself usually refers to the server-side system. For example, the API might be implemented on an Azure Function or AWS Lambda, but the application it is implementing the interface for might be hosted on-premises at some firm’s location. In this case, the serverless API may or may not need to leverage another API to interact with a destination system for requests and may act more as traditional ‘middleware’. Whether the serverless API is included in the system context is not always clear and depends on the system.
Programming
This refers to the API being implemented in code – it is in essence a software program developed using a programming language, implementing some process logic, and which can be compiled into or interpreted as machine code and executed by the computer. Generally, the program will have abstractions that allow a programmer to develop a system that can parse and interact with messages being received on various ports and do something with the data contained therein (execute a function, transform data, retrieve data, produce a response message, etc).
Interface
This refers to APIs being interfaces, as described above. Really, you can think of API’s as ‘interfaces as code’.
A good API design practice includes:
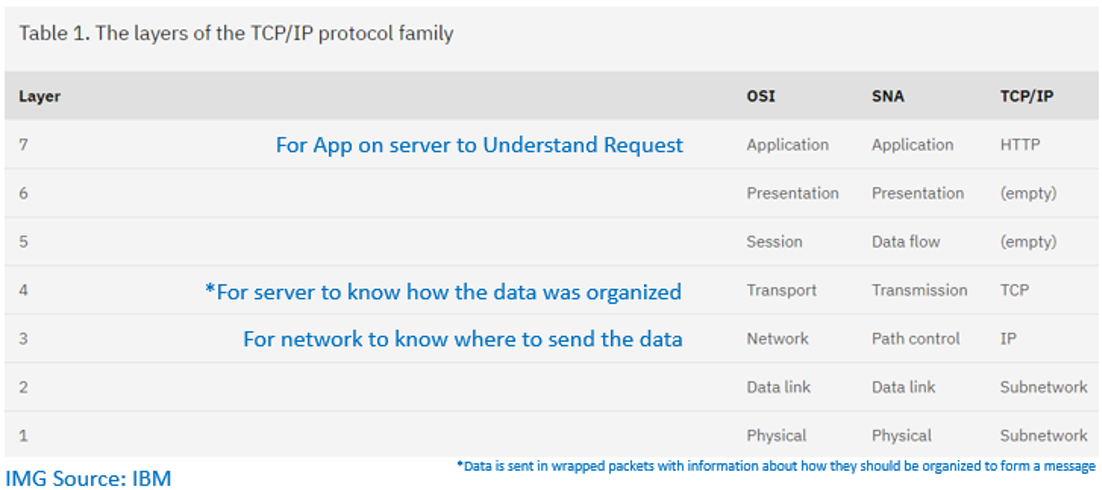
Hypertext Transfer Protocol (HTTP) is an application-level protocol used to transfer data over a computer network. It’s a way to wrap some message (containing data, requests, etc.) along with a destination address, and some metadata about the content and intent of the message. It’s usually sent via TCP/IP, a networking protocol.
Think of HTTP as a way for a client (an app on your computer) to structure data into a request for some data resource (from an app on another computer), and to get a response back, specifically over the web. It provides status codes (like 200, 404, 503, etc.) in response messages. Think of TCP/IP as a way to package up data so that it knows where to be sent over a network and the internet.
When HTTP requests are successful:
You see a status code ‘200’.
When HTTP requests are not successful:
You see a status code of 400-499 for client errors and 500-599 for server errors.
Common client errors:
‘404’, meaning not found & ‘400’ meaning bad request.
Sometimes we need to send or provide in a response additional information with an HTTP request such as metadata about the content or information that isn’t related to the content of the message itself, like security tokens.
For that, we use headers. Headers work like key:value pairs, with a header name and a string value. A common header, for example, is ‘Accept’, which tells an API what representation is being requested. Another is ‘Content-Type’, which refers to the representation/media(MIME) type of the message content. For example, you may see a header like – Accept: “application/json”. There are 3 normal types of headers: request, general, and representation. ‘Accept’ is a request header, meaning it pertains to the request itself, whereas ‘Content-Type’ is a representation header, referring to the representation of the contained content of the message.
If we were going to make an analogy to a service we understand, like a mailing service, HTTP would be an envelope. On the envelope, you might write an address, who it’s being sent to, and other information like instructions about who should open the message, and maybe even what language it’s written in. That’s essentially what HTTP is, wrapping up information inside! Usually that information is application-level serialized data – usually either html and media for rendering in a browser or JSON or XML format data. HTTP also includes a method: GET, POST, PUT, DELETE, or PATCH. These requests may be accepted or denied based on the format or validity of the message.
In this analogy, the mail is taken from you, and carried by a mail carrier to a different address, and delivered (in this case, TCP would be carrying the mail and IP would be directing it to the destination address). In this analogy, the recipient of your email hands a letter back to the mail carrier and delivered back to your address. The mail contains a message saying whether they could perform the request (on the ‘envelope’ HTTP response), and if so, content (the requested information or response/validation of the request contained inside).
An example layout of an HTTP Request:
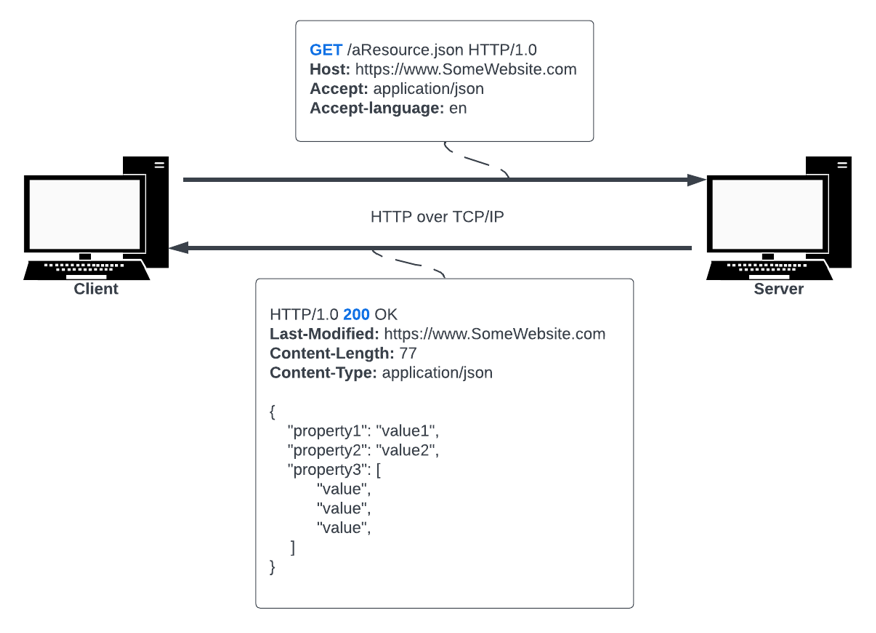
Representational State Transfer (REST) is a way of designing APIs to standardize and simplify the way it receives HTTP requests. REST isn’t a protocol or a technology but is instead just a set of rules/standards. To use REST, we should seek to understand its standards.
First, lets break down the terms:
Representational
This adjective implies that the Interaction occurring over the interface concerns the translation, migration, transformation, manipulation, etc. of “representations” of some data resource. When you say ‘representational’, think of the verb ‘represent’. How do you represent something? Maybe we want to represent a student – you could ‘represent’ a student in JSON (the web-standard and native way to represent data over APIs) or XML in this way:
JSON:
[
{
"StudentID": "001",
"StudentName": "Andy"
}
]
XML:
<student>
<StudentID>001</StudentID>
<StudentName>Andy</StudentName>
</student>
Note that our representations are essentially abstractions of real-world domain objects, if designed well containing only the necessary properties needed to distinguish it adequately and support functions and decision support frameworks supporting some use case of your system. In this sense, the ‘resources’ we are referring to and representing can often be thought of in the same way as database records, or classes, or even blocks representing system elements in a block-definition diagram – all different logical, relational, conceptual, or other kinds of abstractions or views of real-world objects/instances that are specialized representations or views to support the technologies or processes they’re involved in.
State
‘State’ in this context is a noun that refers to the condition or way of being that some entity has. In the case of APIs, the state we’re referring to is the current state of the resources concerned with the HTTP request to the API, which are viewed via representations (usually JSON or XML). For a REST API, this implies that our request concerns the state of the resource.
Transfer
The last word is a verb referring to what we’re doing with the state of the resources. In our HTTP requests, what we’re essentially seeking to do is provide a method and information about how we would like to alter or translate the state (values, location, organization, etc) of the resource at the end point. A request may simply be asking to retrieve and provide back a resource (GET), but it may also be seeking to update a whole resource (PUT), add an entirely new resource (POST), remove a whole resource (DELETE), or update individual properties and values of a resource (PATCH). Of the aforementioned methods, POST, PATCH, and PUT will almost always require that the request provide a representation of the resource or its properties in the HTTP content and in a format and structure that will be provided by the API within its documentation.
For an API to be a REST API, it shouldn’t need to send any information about its current state (data or otherwise) during the process, and the server shouldn’t store any information about the client’s state. That means that all request messages should only have data about and be concerned with the state of the resources on the server. This means that the server has everything it needs to know from the client in the initial message to process an HTTP request and will not need to ‘ping back the client’.
The API should provide or alter resources upon proper-formatted request, and everything it provides or alters in the content should be considered a “resource”. Every resource should be identified by a unique Uniform Resource Identifier. Abbreviated as URI – this identifier is usually some unique web address created by passing url parameters or specially-formatted JSON in the request content body for querying, but one address can also provide multiple URIs as GUIDs per resource.
Additionally, the API should provide some representation of the resources being altered. These representations are usually JSON or XML. Clients request specific representations, and servers provide them.
Lastly, a REST API should provide a standard set of constraints and possible actions (methods) to simplify working with resources. These are the aforementioned GET, POST, PUT, and DELETE methods – to indicate we would like to create, read, update, or delete (CRUD) resources.
See the below example of an HTTP (implied GET) request made through a browser to the Microsoft SharePoint API, which by default provides XML representations of resources.
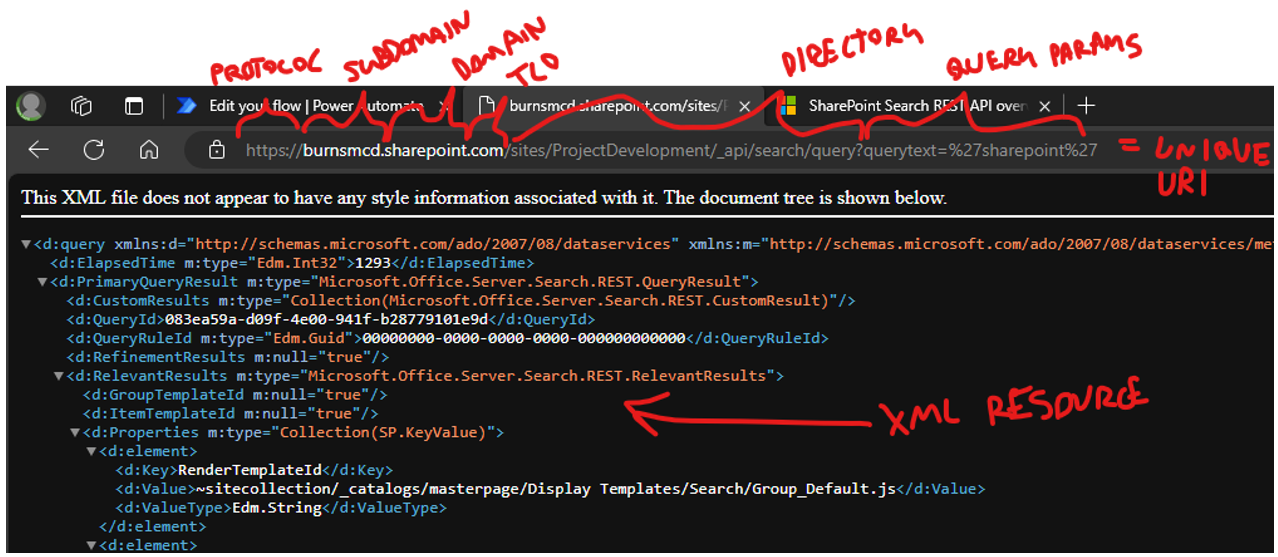
Unique URI generally consists of the protocol (http/https), a subdomain, a domain name, and a top level domain followed by a forward slash indicating a directory, and optionally some query parameters depending on the API design. In an HTTP Request, you don’t need to pass the Host request header always – you can pass a full URL as the resource identifier in the GET request. That said, sometimes it can be useful to split it up.
These resolve the IP Address. The directory determines routing to a web server that will return data. Many web server endpoints return web pages (HTML and some image and text media), but some web server endpoints represent REST APIs and return resources (XML or JSON).
Although this article is just an introduction providing basic concepts and definitions, I plan to provide more writings and content related to Systems Integrations for software-intensive and purely-software systems, including some projects and walkthroughs (such as model-based API design using Oracle Data Modeler and forward engineering techniques, or GraphQL Server Development with API Stitching use cases).
© Hillier Engineering | 2024