
Conceptual classes can be described as:
“… A pre-defined, syntactic grouping of data (primitive datatypes representing
characteristics and user-defined datatypes), properties (to access or set
data), and methods, generally arranged and selected to provide a useful representation of a business or domain object.”
We also generally referred to classes as “User-Defined types”.
In object-oriented programming, classes are one of the most generalized abstractions
of information. Classes are templates for objects – or stored data and machine code in
memory at runtime which interacts with other machine code/stored data. Classes are used
to represent business or other domain entities/objects, abstractions of groupings/controllers/managers of objects, and
user interfaces.
The items contained in classes – data/fields/attributes, actions/methods/functions, properties, constructors, etc. are referred to as members. These items are usually represented in model form via a class diagram (a type of UML model) that displays a class, its attributes, its methods, and its associations. Below is an example of a class, with attributes and methods.

A class’s attributes are usually referred to as its data members, while its methods are referred to as it’s behavioral members. Properties, constructors, and other class items aren’t shown in these UML diagrams. When classes contain other classes as data members (such as a human class having an attribute which consists of a collection of cat classes), that is referred to as an association between classes, which are shown as lines between classes within these diagrams.
Other than data and behavioral members, classes have Properties and Constructors. Properties are used to Get or Set an object’s data. Because an object’s data is usually important and potentially sensitive or specifically structured, we want to be able to control how users of an object are able to access its data (like data-access rules). This concept is referred to as Encapsulation – objects have private data accessed in a controlled way via public properties and methods. All class members are considered to be private unless the public keyword (or some other special keyword) is syntactically provided with the member.
Constructors are a special type of class behavioral member, although they tend to stand alone as their own type of class member. Constructors are responsible for handling the creation of an object instance from a class. Using terms we have learned before - knowing that classes are composed of many different primitive datatypes, functions, properties, and constructors – we need a way other than just using the name of a type to handle it’s creation.
When called alongside the new keyword, constructors create an object containing all of a class’s defined members, usually storing that object in a dedicated location in RAM called the heap (Classes are named as variables are), and often also accepts instantiation parameters (explained in the next section) in order to assign values to an object’s variables upon creation.
Below is an example of a class defined syntactically in C# syntax, as opposed to a UML diagram – as well as the demonstrated use of a constructor and property:
public class SmartPhone // A custom, User-Defined Type
{
// Data Members (primitive datatypes and other classes)
string phoneNumber;
string phoneModel;
string caseColor;
double displaySize;
string carrier;
// Properties (to access Data Members)
public string PhoneNumber
{
get => phoneNumber;
set => phoneNumber = value;
}
// Behavioral Members (methods/functions)
public void Call() {…}
public void Answer() {…}
public string GetCurrentLocation() {…}
public double CalculateNumber() {…}
// Parameterized Overload Constructor
public SmartPhone(string pN, string pM, string cC, double dS, string c)
{
phoneNumber = pN;
phoneModel = pM;
caseColor = cC;
displaySize = dS;
carrier = c;
}
}
public class MyClass
{
SmartPhone AndysPhone;
public void ConstructPhone(string pN, string pM, string cC, double dS, string c)
{
//instance created of above smartphone object
AndysPhone = new SmartPhone(pN, pM, cC, dS, c);
}
public string GetNumber()
{
//property used to access phonenumber
return AndysPhone.PhoneNumber;
}
}
Reading this lecture note, you should already be semi-familiar with using classes despite not making your own. For example, a windows form within visual studio is a class. This class has data members, constructors, properties, and behavioral members. Form controls are object data members of the Form class, which can have their own properties, and which are encapsulated by their parent form classes.
In C#, we can create our own types of data, with their own characteristics and behavior by creating custom classes. Classes are used as templates to generate objects at runtime, which are abstractions of stored data and instructions in memory.
The below code represents, for example, a student class:
// server
class Student
{
// data members
string name;
DateTime birthday;
int age;
string studentID;
// default constructor
public Student()
{
//
}
}
In order to create a new instance of this student class, we would need to create an instance of it via a statement in the caller/client, using some user-defined identifier (variable), the new keyword, and the class’s constructor:
// client/caller
Student aStudent = new Student();
Note that this creates a new student object, but that object’s data has yet to be set – in the student class, data members are declared, but never assigned to. Furthermore, all of the data members in the above student class are private by default, meaning that they can’t be accessed externally (by the client/caller). In order to make the newly created object usable, we will need to adjust our student class. Below, we turn the default constructor into a parameterized constructor by adding parameters within the constructor’s brackets. We then use those parameters as assumed arguments.
// server
class Student
{
string name;
DateTime birthday;
int age;
string studentID;
// parameterized constructor and data member assignment
public Student(string _name, DateTime _birthday, int _age, string _studentID)
{
name = _name;
birthday = _birthday;
age = _age;
studentID = _studentID;
}
}
We can then create a new instance of the student class by passing values into the parameterized constructor, in order to set its data members:
// client/caller
Student aStudent = new Student("Tyler", new DateTime(2000, 9, 25), 22, "2597142");
The new student object created will now be constructed with actual values assigned to its data members. One issue we still have is access. Because the data members are private by default, and we shouldn’t expose the data members to outside classes because of encapsulation (read below), we need to provide a way for the client to access the data if the object is meant to be mutable (editable after creation). We do this by use of public properties or methods. Below, we adjust the student class to add public properties and methods, such that the caller can access the object’s data.
// server
class Student
{
string name;
DateTime birthday;
int age;
string studentID;
// access data via public properties
public string Name
{
get => name;
set => name = value;
{
public Student(string _name, DateTime _birthday, int _age, string _studentID)
{
name = _name;
birthday = _birthday;
age = _age;
studentID = _studentID;
}
// access data via public methods
public string GetStudentID()
{
return studentID;
}
}
// client/caller
Student aStudent = new Student("Tyler", new DateTime(2000, 9, 25), 22, "2597142");
Console.WriteLine($"Name: {aStudent.Name}, ID: {aStudent.GetStudentID()}");
Classes/custom types aren’t only useful by themselves – they’re useful when related to each other through associations. A class association is a relationship between classes that allows objects to pass data between each other (communicate) at runtime. Lets learn how to implement associations by looking at several examples. Say we have two classes, a student class and a course class, a many-to-many relationship:
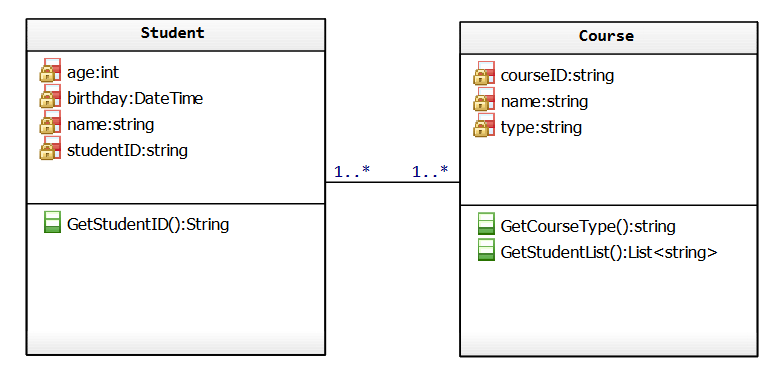
We implement this relationship as follows, by adding them as data members of each other with appropriate multiplicity given the relationship:
class Student
{
// data members
List<Course> enrolledCourses;
string name;
DateTime birthday;
int age;
string studentID;
}
class Course
{
// data members
List<Student> enrolledStudents;
string courseName;
string courseType;
string courseID;
}
Say instead we have two classes, an owner class and a pet class, a one-to-many relationship:
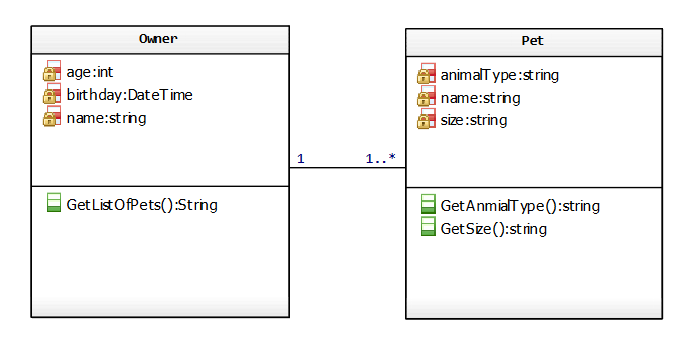
We implement this relationship as follows:
class Owner
{
// data members
List<Pet> ownedPets;
string name;
DateTime birthday;
int age;
}
class Pet
{
// data members
Owner owner;
string animalType;
string name;
string size;
}
Lastly, say we have two classes, a person class and a passport class, a one-to-one relationship.
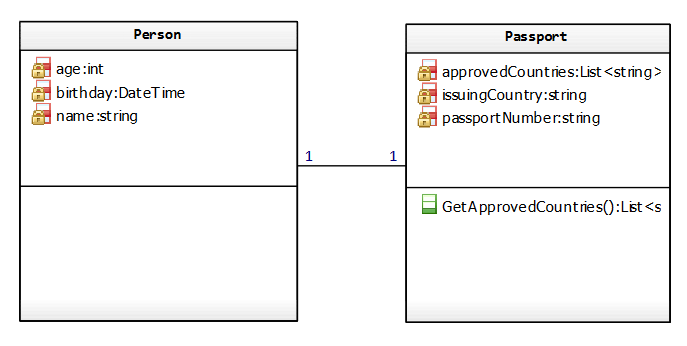
We implement this relationship as follows:
class Person
{
// data members
Passport theirPassport;
string name;
DateTime birthday;
int age;
}
class Passport
{
// data members
Person passportHolder;
List<string> approvedCountries;
string issuingCountry;
string passportNumber;
}
We can extend this concept to our Windows Forms knowledge. Forms are a class – so we can create association between forms and our custom classes. Say we have a form that is meant to capture personal information.
We can create a personal information class (to act solely as a custom data structure for personal information, without methods, with one public property for access):
class Personal_Information
{
// data members
string name;
string address;
string phoneNumber;
string age;
// public property to return multiple pieces of data in one package
public string[] PersonInfo
{
get => new string[4] { name, address, age, phoneNumber };
}
// parameterized constructor
public Personal_Information(string name, string address, string phoneNumber, string age)
{
this.name = name;
this.birthday = address;
this.phoneNumber = phoneNumber;
this.age = age;
}
}
Next, we implement a one-to-many association between this class and our system- generated Windows Form class:
public partial class Form1 : Form
{
// data members (in this case, multiple of the ‘Personal_Information’ class)
List<Personal_Information> personInfo;
// default constructor
public Form1()
{
InitializeComponent();
// initialize runtime objects in the default constructor or a method as needed
personInfo = new List<Personal_Information>();
}
}
Now that we have a way to create and reference each of the Personal_Information class instances we can create instances, store those in our list, and access them as needed:
public partial class Form1 : Form
{
List<Personal_Information> personInfo;
public Form1()
{
InitializeComponent();
personInfo = new List<Personal_Information>();
}
private void btnAdd_Click(object sender, EventArgs e)
{
personInfo.Add(new Personal_Information(txtName.Text,
txtAddr.Text,
txtPhone.Text,
txtAge.Text));
txtName.Clear();
txtAddr.Clear();
txtAge.Clear();
txtPhone.Clear();
RefreshPeople();
}
private void RefreshPeople()
{
lstPeople.Items.Clear();
foreach (Personal_Information pi in personInfo.ToList())
{
lstPeople.Items.Add(pi.PersonInfo[0]);
}
}
private void lstPeople_SelectedIndexChanged(object sender, EventArgs e)
{
string name;
name = lstPeople.SelectedItem.ToString();
foreach (Personal_Information pi in personInfo.ToList())
{
if (name == pi.PersonInfo[0])
{
lblName.Text = pi.PersonInfo[0];
lblAddress.Text = pi.PersonInfo[1];
lblAge.Text = pi.PersonInfo[2];
lblPhone.Text = pi.PersonInfo[3];
}
}
}
}
Below is a form designed to capture data which we will store in each instance of the Personal_Information objects we initialized above within our form class.
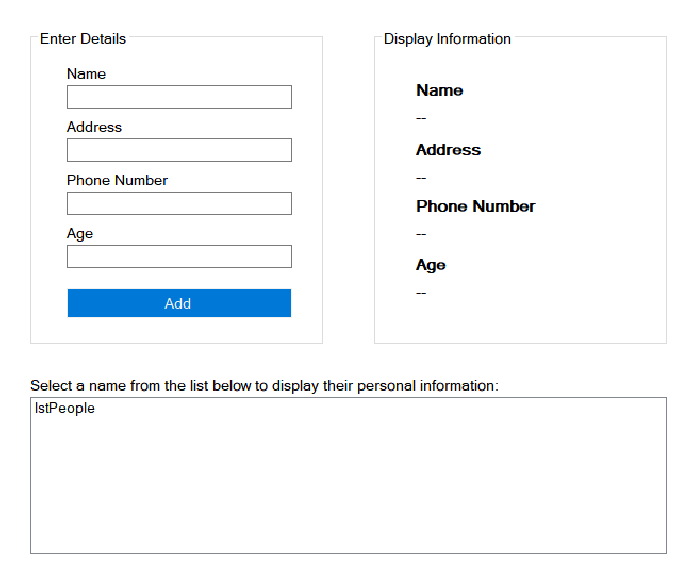
Every time the user clicks ‘Add’ (btnAdd), a new Personal_Information object will be initialized. The text contained within the Name (txtName), Address (txtAddr), Phone Number (txtPhone), and Age (txtAge) textboxes of the form will be used as constructor initializers, by passing them as arguments to the parameterized constructor of the Personal_Information class. Then the textboxes will be cleared.
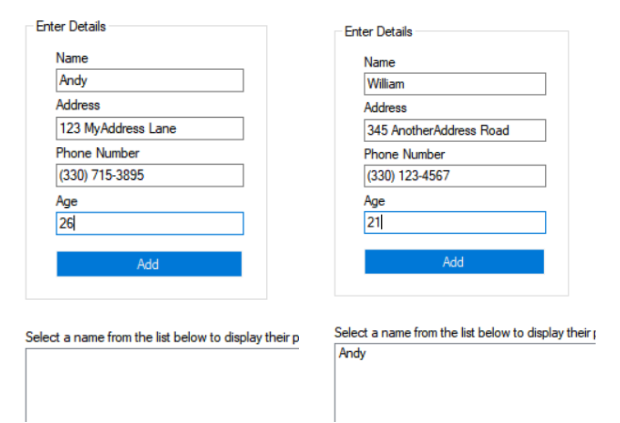
A Refresh() function will be used to read the form’s list of Personal_Information objects,
and populate the listbox with each of the objects’ name field. When the user selects a
name from the listbox, it will update the labels in the ‘Display Information’ Group Box.
Note: I know the phone number and age are in the wrong spots in the below images!
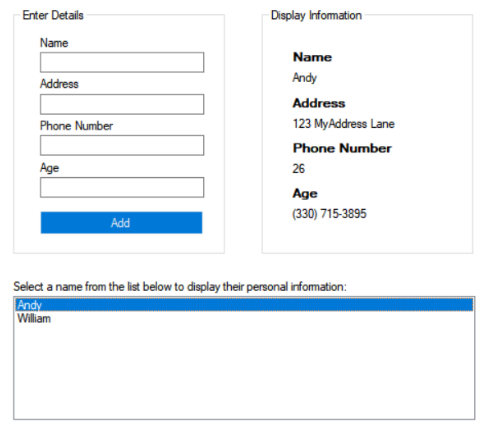
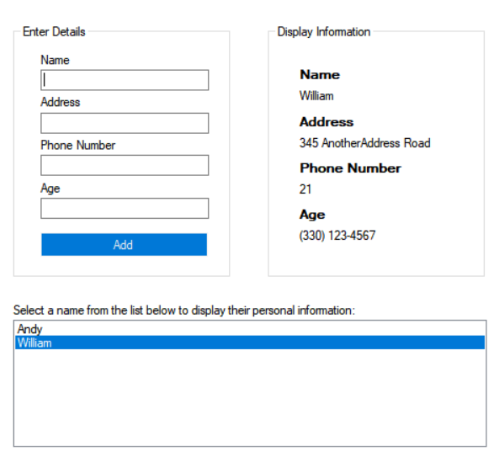
One of the main pillars in object-oriented programming (OOP) is encapsulation. What is encapsulation? Why is it of benefit OOP? Why should we enforce it?
One of the main benefits of encapsulation is access control to data structures, including primitives and other objects. Encapsulation essentially refers to restricting the access to an object’s data members, and only allowing access through a controlled ‘gateway’. In C#, this would be public properties and methods. In other languages, this may more generally refer to get/set methods and properties. Remember that in some languages, properties and attributes/data members are synonymous. In C#, properties are almost exclusively referring to get/set methods.
Unlike more functional programming languages such as F#, Haskell, and R, immutable data structures (un-changeable) are not a feature - but immutability is still a necessity in practice (remember that data structures are defined as a purposeful organization of data – these structures could be objects, lists, arrays, or other structures such as structs, enumerations, stacks, queues, etc).
In object-oriented programming, because mutation (change) is allowed within objects and data structures, we need to control that data’s mutation. Why do we need to control data mutation? To ensure that our software acts in a predictable way, to ensure that objects who are relied on by other objects as servers provide the data needed to perform its intended operations, and to ensure that multi-threaded operations aren’t trying to process data in a shared location (risk of thread-lock). If a data structure is a purposeful organization of data, then mutability is a way for that purpose to become more generalized or less purposeful, lowering the overall utility of each object. While mutability can make individual objects more dynamic, it can also make them less purposeful, which is a balance we need to consider and strike properly within object- oriented programming.
Mutation can cause polymorphic (see next lesson on polymorphism) methods/functions to behave in unexpected ways, can cause threads to lock, can cause objects to hold data that it was not intended to, and cause many, many other issues. In general, immutability enforcement allows us to create new objects every time new data is needed. Paired with a way to reference specific objects at runtime, this gives us the ability to version objects and ensure that a specific object version will act in an expected manner.
What specifically does encapsulation refer to? Encapsulation refers to the purposeful design of a class to allow protection of an object’s data from unexpected mutation by controlling access to that data. This access is controlled by default. If you make a new class in C#, you will notice that all data members will be private by default. The keyword ‘private’ ensures that all data members will be inaccessible by clients/caller objects. The default ‘private’ status of data ensures that the data is unable to be changed in ways that aren’t controlled and expected.
Although the data members of classes are mutable – we can make them essentially immutable or control the level of mutability of any given data member by controlling how/when that data is accessed, to help manage class service expectations. Properties and encapsulation can also make data easier to access and work with by providing public data structure abstractions that can provide controlled access to the underlying object data. One example in creating public data structures as a member of a class that provide access to object data via an enumerable sequence or structure as opposed to individually accessed pieces of data.
The ‘PersonInfo’ property in the previous section’s form example takes several data members and packages them in a more portable data structure (a list) to make the data easier to work with:
…
class Personal_Information
{
// data members
string name;
string address;
string phoneNumber;
string age;
// public property to return multiple pieces of data
public string[] PersonInfo
{
get => new string[4] { name, address, age, phoneNumber };
}
…
Conceptually, a class is a user defined type. But among types of conceptual entities and elements, there are usually many different layers/levels of abstraction. For example, one could define a clothing class, that holds data and methods for conceptual clothing. One could also define a shirt class, a pants class, a hat class, etc. – which are all types of clothing.
When we want a type’s data and methods to be compatible with and conform to its generalized type (for example, a shirt should be an extension/specialization of clothing), we implement Inheritance, one of the main pillars of object-oriented programming.
Inheritance is implemented in object-oriented programming when one object is a type of another object, or when one object is a specialization of a more generalized object. We refer to the generalized class/type (that which is being inherited from) as the base class or supertype. We refer to the specialized class/type (that which is inheriting) as the derived class or the subtype.
When we indicate that one class is a higher-level abstraction of another (such as clothing being a higher-level abstraction of hats, shirts, pants, skirts, etc.), that indication is referred to as a generalization.
When we indicate that one class is a lower-level abstraction of another (such as hats, shirts, pants, skirts, etc. each being a lower-level abstraction of clothing types), that indication is referred to as a specialization.
So how does inheritance work in concept? It’s always a ‘type of’ relationship, that only works in one direction. Consider the above example with clothing. Shirts are a type of clothing, but clothing is not a type of shirt. Shorts are type of clothing, but clothing is not a type of shorts. ‘Clothing’ generalizes shirts and shorts. Shirts and shorts specialize clothing.
Here is another example - menu items at a drive-thru restaurant. A burger is a type of menu item, but a menu item is not a type of burger. A drink is a type of menu item, but a menu item is not a type of drink. ‘Menu item’ generalizes burgers and drinks. Burgers and drinks specialize menu items.
Yet another example – types of animals. A mammal is a type of animal, but an animal is not a type of mammal. An amphibian is a type of animal, but an animal is not a type of amphibian. ‘Animal’ generalizes mammal and amphibian. Mammal and amphibian specialize animal.
Source: https://cdn-fusionreactor.pressidium.com/wp-content/uploads/2020/09/2.outfile-2.png
These relationships in and of themselves are not inheritance, just levels of abstraction. But classes which represent specializations and generalizations of one another are pertinent to the effective implementation of inheritance and imply classes that will benefit from it.
In object-oriented programming, Inheritance is the practice of passing down data from a base class/supertype to its derived classes/subtypes. In C#, this is performed with the understanding that the data is passed from base class to derived class in a one-to-one or one-to-many relationship (single inheritance). This means that any given derived class can inherit from one and only one base class, or from no class at all (there is somewhat of a work-around for this described later if needed, referred to as interface-based programming. Languages like Java support multiple inheritance).
We should note that among the members of a base class passed to a derived class, only data members and behavioral members are inherited. Behavioral members can not be overridden by the derived class unless they are virtual methods. Constructors (including parameterized constructors) are not inherited.
When should we implement inheritance? When a specialized type should hold all of the same data and behaviors as its generalized type but needs its own implementation and/or extension in functionality to fulfill its intended service. Let us implement one of the examples above by creating a menu item class (assuming that every menu item has a name, a price, an availability range like times of day, and a status such as ‘standard’, ‘seasonal’, or ‘limited’).
public class MenuItem
{
// data members
protected decimal price;
protected TimeSpan availability;
protected string status;
protected string itemName;
// public default property
public MenuItem()
{
//
}
}
Now we will create specializations of the more generalized MenuItem type: burger, drink, and sides.
public class Burger : MenuItem
{
// data members
string size;
int burgerCount;
bool hasCheese;
bool hasTomatoes;
bool hasLettuce;
}
public class Drink : MenuItem
{
// data members
int sizeOz;
bool isIced;
bool isSweetened;
bool containsDairy;
}
public class Side : MenuItem
{
// data members
bool isComboEligible;
}
Notice in the specialized classes above the highlighted syntax – the colon symbol ‘:’ allows us to specify a base class, in order to make our specialized class a derived class, meaning that it inherits all of its data members. This means that without explicitly defining it in the inheriting class, those data members belong to it.
There would be one problem though if we wanted to have direct access to those inherited data members. Because the derived class is still a separate class, in order to give a derived class access to the otherwise completely private data members of the base class, we use the keyword ‘protected’ for the base class’s data members.
Per the Microsoft Documentation:
“A protected member is accessible within its class and by derived class instances. A protected member of a base class is accessible in a derived class only if the access occurs through the derived class type.”
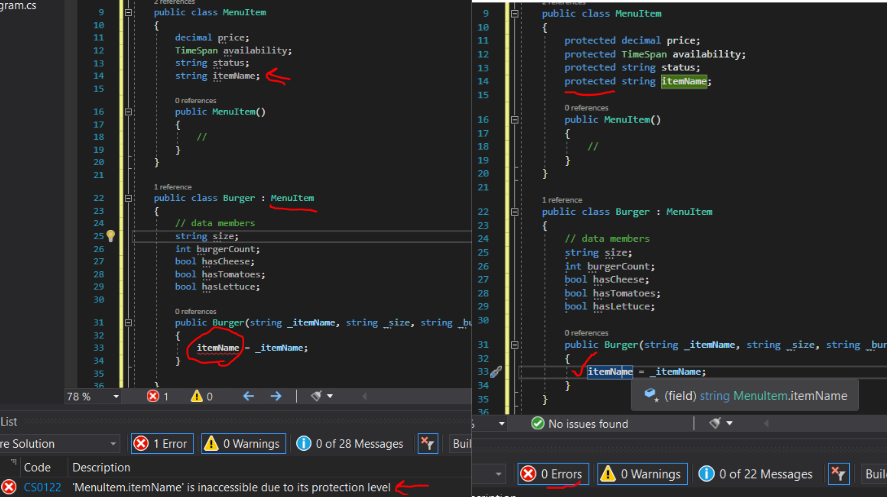
Above, we can see this is true when we attempt to set the MenuItem data member of its derived burger class using a constructor initializer – we are unable to set that member due to its protection level. This issue is resolved when we give the needed base class members a ‘protected’ access level.
The same issue will also arise when trying to use the inherited base class data through methods or properties:
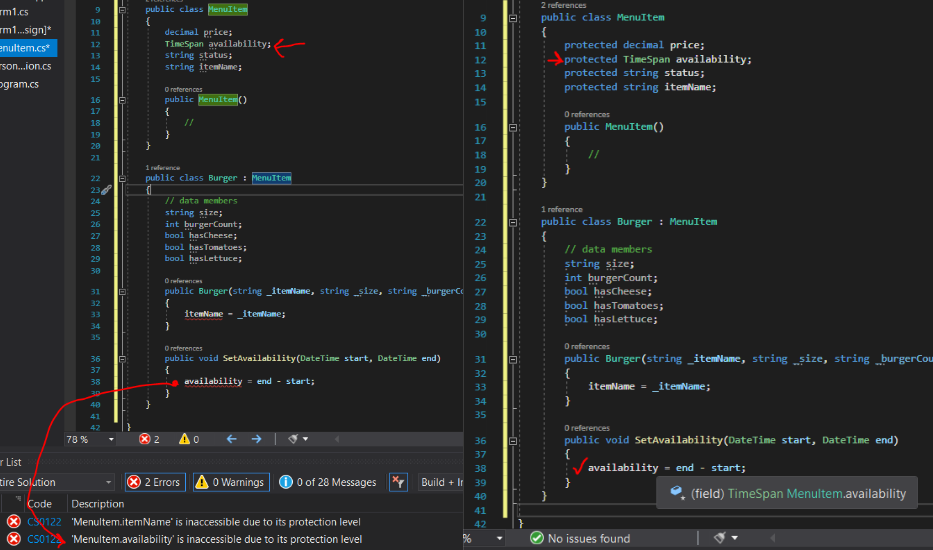
This issue is resolved when we give the needed base class members a ‘protected’ access level.
When we make base classes when starting out, it is useful to make each of the base class’s private members protected members in order to ensure that the derived classes can make use of the data directly. If we want derived classes only to have indirect access to a member, we make that member private and create a property to control its access.
Polymorphism, after encapsulation and inheritance, is considered the last main pillar of object-oriented programming. Polymorphism sounds like a complex word, but we can break it down: ‘Poly’, meaning ‘many’, and ‘morphism’ meaning ‘mapping between two objects of some abstracted category’. ‘Morph’ itself means ‘to change the form or character of'. Combining all of these definitions together, we can start to piece together what polymorphism is in concept. We can replace the word ‘polymorphism’ with the phrase ‘many forms’, and it would be an adequate substitute.
Polymorphism is a characteristic of object-oriented programming languages that allows objects of the same abstract category to exhibit many different behaviors or provide many different services for only one client-visible action. Polymorphism is implemented in C# by leveraging abstract classes/properties, virtual method overriding of base classes by derived classes, and internal method overloading. Polymorphism also refers to the multiple implementations of a single interface (interfaces are covered shortly later).
Within visual studio, you likely have already come across the word ‘overloading’. Overloading a method is a practice which allows you to provide several implementations for one method identifier within a single class, so long as the method signature (type and order of parameters) is different. This is one way to implement polymorphism – one method from the client-visible side can perform multiple actions or provide multiple services depending on the types of the arguments passed to it. We refer to each implementation as an ‘overload’ of that method.
Below is an example from visual studio of an overloaded method:
public string GetSize()
{
return size;
}
public string GetSize(string format)
{
if (format == "firstChar")
{
return size[0].ToString();
}
return size;
}
Note that both method definitions share the same identifier ‘GetSize’, but have different implementations. This is allowed because the second definition has a string as the first parameter, giving it a different signature from the first, which has no parameters. Note that the return type does not make a difference in overloading – overloading is not allowed unless the parameters are of different types for one method identifier.
Methods can have any number of overloads. For example, the static class Convert’s ‘.ToString()’ method has 36 overloads:
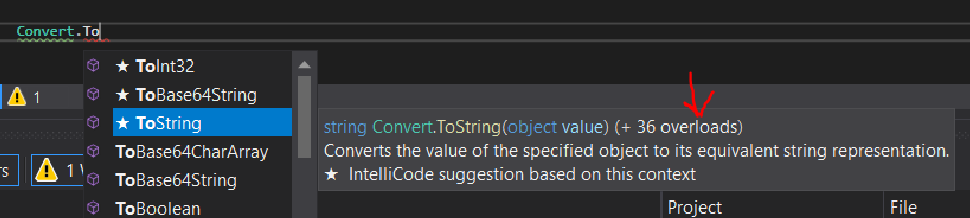
From the client side, the method will appear as one method (see above), with several different options for passing arguments, which are dependent on the overloaded method signatures defined on the server side. The arguments passed will inform the server class as to which method’s statements to execute.
Besides overloading, C# allows for the implementation of polymorphism via overriding virtual methods. A virtual method is a method of a base class that uses the virtual keyword. According to Microsoft:
“The virtual keyword is used to modify a method, property, indexer, or event declaration and allow for it to be overridden in a derived class”
Essentially, you can use the word ‘virtual’ to allow specialized types of more general abstractions to perform their behaviors in their own way while only calling a single method to do so. A classic demonstration of this concept uses shapes (a generalized abstraction) with specialized derived classes consisting of squares, circles, and triangles, who each have their own way of calculating their area. As we know from geometry class, the area of a square is defined as ‘length * width’, the area of a circle as ‘π * radius2’, and the area of a triangle as ‘½ base * height’. Knowing this, we would implement a GetArea() method in different ways depending on the type of shape in question. In order to override the virtual method, we use the keyword ‘override’ in the derived class’s implementation of the method:
public abstract class Shape
{
// virtual method
public virtual double GetArea()
{
return 0.0;
}
}
public class Square : Shape
{
// extended data members
double length;
double width;
// parameterized constructor
public Square(double l, double w)
{
length = l;
width = w;
}
// override method
public override double GetArea()
{
return length * width;
}
}
public class Circle : Shape
{
// extended data members
double radius;
// parameterized constructor
public Square(double r)
{
radius = r;
}
// override method
public override double GetArea()
{
return Math.PI * Math.Pow(radius, 2);
}
}
public class Triangle : Shape
{
// extended data members
double base;
double height;
// parameterized constructor
public Square(double b, double h)
{
base = b;
height = h;
}
// override method
public override double GetArea()
{
return (0.5 * base) * height;
}
}
Now, if a client creates a list of shapes and wants to calculate the total area of all of them, it can do so with only one method call, without needing to explicitly check the types (thanks to inheritance and polymorphism):
public partial class Form1 : Form
{
List<Shape> myShapes;
public Form1()
{
InitializeComponent();
// Add 3 different types of shapes to our List<Shape>
myShapes = new List<Shape>
{
new Square(2.0, 4.0), new Circle(3.5), new Triangle(3.0, 5.0)
};
}
public double CalculateTotalArea()
{
double area = 0;
foreach (Shape s in myShapes)
{
// GetArea() calculates based on override of derived class type of shape ‘s’
area += s.GetArea();
}
return area;
}
}
Polymorphism is a great way for us to leverage inheritance in order to avoid type- checking and provide extended functionality to a category of class.
Note that in the above-defined Shape class, we referred to it as an ‘abstract’ class. An abstract class is defined using the ‘abstract’ keyword, and it not meant to be initialized into an object, but instead exists solely to pass its members to its derived classes. Often in application, base classes shouldn’t allow objects to be instantiated, as they are too abstract to be useful. In the case of shape – how do you calculate the area of a shape? It depends on the specific shape.
If we were to add a ‘new Shape()’ to the list in Form1 above, how would we calculate it’s area? It would be ambiguous, which is why the Shape class (which was only intended to serve as a base class to the more specialized shape objects) was defined as an ‘abstract’ class.
Composition is a strong form of association that indicates that one object is composed of other objects, which means that the composed object has ownership of the other objects and is responsible for their lifecycle. This means that when the composed object is destroyed, the other objects it is composed of are also destroyed.
Aggregation is a weaker form of association that indicates that one object is made up of other objects, but the composed object does not have ownership of the other objects and is not responsible for their lifecycle. This means that when the composed object is destroyed, the other objects it is made up of are not destroyed.
Composition and aggregation can be used in a variety of class-association contexts. For example, consider a Car class that is composed of an Engine object and a Transmission object.
The Car class has ownership of the Engine and Transmission objects and is responsible for creating and destroying them. This is similar to how a real car is composed of many different parts. In most cases, if you were to get in an accident and need to dispose of the car, you would likely dispose of the entire car including its parts. Additionally, most parts are engineered to fit a specific type of car and are specialized and unique to that car. Here is an example of how to implement a Car class that is composed of an Engine and a Transmission:
public class Car
{
Engine engine;
Transmission transmission;
public Car()
{
this.engine = new Engine();
this.transmission = new Transmission();
}
}
In this example, the Car class is composed of an Engine and a Transmission, and it is responsible for creating and destroying them (note the ‘new’ keyword) – the Engine and transmission do not exist outside of the Car class.
Now let's consider an example of aggregation. Suppose we have a Department class that is made up of several Employee objects. The Department class does not have ownership of the Employee objects and is not responsible for their lifecycle. This makes sense if you think about it: Departments have an association to employees, but an employees can leave departments, switch departments, or leave altogether (and in a business information systems context, become inactive). So the association is not as strong as in the car example.
Here is an example of how to implement a Department class that is made up of several Employee objects:
public class Department
{
List<Employee> employees;
public Department(List<Employee> employees)
{
this.employees = employees;
}
public void UpdateEmployees(List<Employee> employees)
{
this.employees = employees
}
}
In this example, the Department class is made up of multiple Employee objects, but it does not have ownership of them and is not responsible for their lifecycle – note how this data is provided to the Department from an outside source (see the parameterized constructor initializer), implying the creation and existence of the employee objects outside of the department (they are provided to Department via arguments to the parameterized constructor or the UpdateEmployees() function via dependency injection).
With composition associations, the client creates the object it depends on. In aggregation associations, the client receives the objects it depends on by some external reference (in this case, dependency injection).
Note: Dependency injection is a design pattern in which an object or function receives other objects or functions that it depends on.
Now let's consider an example of composition using Windows Forms. A Form object can be composed of several other controls, such as Command Button and TextBox objects. The Form object has ownership of the controls and is responsible for creating and destroying them.
Here is an example of how to create a Form object that is composed of a Button and a TextBox:
public class MyForm : Form
{
Button button;
TextBox textBox;
public MyForm()
{
button = new Button();
textBox = new TextBox();
Controls.Add(button);
Controls.Add(textBox);
}
}
In this example, the MyForm class is composed of a Button and a TextBox, and it is responsible for creating and adding them to the form's control collection. Finally, let's consider an example of aggregation in C# using Windows Forms. A Form object can be made up of a Panel object, which in turn is made up of several other controls, such as Button and TextBox objects. The Form object is made up of the Panel object, but it does not have ownership of it and is not responsible for its lifecycle.
Here is an example of how to create a Form object that is made up of a Panel object, which is made up of several Button and TextBox objects in C# using Windows Forms:
public class MyForm : Form
{
Panel panel;
public MyForm(Panel panel)
{
Button button1 = new Button();
Button button2 = new Button();
TextBox textBox = new TextBox();
panel.Controls.Add(button1);
panel.Controls.Add(button2);
panel.Controls.Add(textBox);
Controls.Add(panel);
}
}
In this example, the MyForm class is made up of a Panel object, which is made up of several Button and TextBox objects. The MyForm class does not have ownership of the Panel object or the controls it contains and is not responsible for their lifecycle. One important concept to note is that you can’t directly implement composition and aggregation in C# from a perspective of memory management - this is because the process of construction and destruction is highly abstract in C#, and destruction in particular is inaccessible – but that is not to say that you can’t implement it via purposeful placement of logical associations (as above). In other languages, though, such as C and C++, composition and aggregation can be directly implemented, and rules set to ensure full lifecycle control within a class. Before looking to composition, you might consider whether or not single inheritance is a more appropriate solution. In situations requiring something similar to multiple inheritance (like in Java), you may implement that using composition associations.
To implement multiple inheritance using composition in C#, you can create a class that contains instances of the other classes that you want to inherit from, and then delegate the appropriate methods (or properties) to those instances.
Here is an example of how to use composition to implement multiple inheritance in C#:
public class BaseClass1
{
public void Method1()
{
Console.WriteLine("BaseClass1.Method1");
}
}
public class BaseClass2
{
public void Method2()
{
Console.WriteLine("BaseClass2.Method2");
}
}
public class DerivedClass
{
BaseClass1 base1;
BaseClass2 base2;
public DerivedClass()
{
base1 = new BaseClass1();
base2 = new BaseClass2();
}
public void Method1()
{
base1.Method1();
}
public void Method2()
{
base2.Method2();
}
}
In this example, the DerivedClass is composed of instances of BaseClass1 and BaseClass2, and it delegates the Method1 and Method2 methods to those instances. This allows the DerivedClass to inherit the behavior of both BaseClass1 and BaseClass2.
To use the DerivedClass, you can create an instance of it and call the inherited methods as follows:
DerivedClass derived = new DerivedClass();
derived.Method1(); // Outputs "BaseClass1.Method1"
derived.Method2(); // Outputs "BaseClass2.Method2"
Note that using composition to implement multiple inheritance can be more complex and error-prone than using single inheritance, as you need to carefully delegate the appropriate methods and properties to the contained objects. Again, it is generally recommended to use single inheritance whenever possible, and to use composition only when necessary.
Structs are a custom value type (as opposed to reference types, or classes) that represent a “lightweight” object. They are like classes, but they are stored in the stack (like primitive data types) rather than in the heap (where objects/classes are stored), which makes them more efficient for small data types.
There are several common use cases for structs. One use case is representing simple data types that consist of a small number of fields, such as points, rectangles, and complex numbers. For example, you can use a struct to represent a 2D point with X and Y coordinates:
public struct Point
{
public int X;
public int Y;
}
// ...
Point p1 = new Point();
p1.X = 10;
p1.Y = 20;
Point p2 = p1;
p2.X = 30;
Console.WriteLine(p1.X); // Outputs "10"
Console.WriteLine(p2.X); // Outputs "30"
In this example, the “Point” struct has two fields: ‘X’ and ‘Y’. You can create an instance of the Point struct and set its fields as needed. You can also create a copy of a Point struct using the assignment operator. Note that structs are value types (as opposed to reference types), so creating a copy of a struct creates a new instance with its own copy of the data. Another common use case for structs is implementing lightweight objects that do not need the full functionality of a class, such as small data structures or simple entities. For example, you can use a struct to represent a 2D vector with X and Y components:
public struct Vector2D
{
double x;
double y;
public Vector2D(double x, double y)
{
this.x = x;
this.y = y;
}
public double Length()
{
return (double)Math.Sqrt(x * x + y * y);
}
}
// ...
Vector2D v1 = new Vector2D(3, 4);
double length = v1.Length();
Console.WriteLine(length); // Outputs "5"
In this example, the Vector2 struct has two fields: X and Y, and a constructor that initializes those fields. It also has a Length method that calculates the length of the vector using the Pythagorean theorem.
Structs can be useful for implementing lightweight objects that do not require the full functionality of a class, such as data structures or simple entities. However, it is important to keep in mind that structs are value types, so they behave differently than classes in some situations, such as when they are passed as parameters or when they are used in collections (in which cases copies are made of them, making implementation of struct associations more difficult without the low-level access to memory allocations provided by other languages). There are a few differences between structs and classes:
In addition to structs and classes, C# also provides a third non-primitive data type called enumerations, or enums. Enums are used to define a set of named constants, which can be used to represent a fixed (immutable) set of values.
Here is an example of an enum:
public enum Days
{
Monday,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday,
Sunday
}
// ...
Days today = Days.Monday;
if (today == Days.Saturday || today == Days.Sunday)
{
Console.WriteLine("It's the weekend!");
}
else
{
Console.WriteLine("It's a weekday.");
}
In this example, the Days enum defines a set of named constants representing the days of the week. The today variable is of type Days and is initialized to Days.Monday. The code then checks whether the value of today is Days.Saturday or Days.Sunday, and prints an appropriate message.
Enums are useful for defining fixed sets of values, such as the days of the week or the suits in a deck of cards. They can make your code more readable and maintainable by providing named constants rather than hardcoded values.
© Hillier Engineering | 2024